I’m starting to create an application for Enonic with the purpose of helping editors / developers with the management of content types.
I’ve only worked the last weekend on it, so it’s in a very early stage of development.
The reason for this post is that I’d like to share what I’ve created by now and also check if you guys think that it’d be a great feature to have, helpful for the community, etc…
As I’ve said, it’s still in a very early stage. I’ve just recorded it to show the main idea behind the app that I’ll be working on.
I’m open to receive suggestions and everything, so feel free to comment on this post your opinions about it!
My plan for this app is to let the user manage everything related to content types. In the video I showed a simple creation, but the plan is to have a full create, read, update and delete.
Where am I expected to be updating the development process of the app? Can I post here the updates about it?
If I were you, I would put my focus in helping developers create better quality data models, and content creators creating better quality data.
And that is not easy!..
Better data models
Here are some points where I think developers often can improve, when creating models:
Not making enough fields mandatory (<occurences minimum="1" maximum="1" />). I think this should be your default setting
Are your field labels immediately intuitive for content creators? There is maybe not much we can do automatically here, but maybe some text to guide data modelers to create more intuitive labels, and help texts.
Too complex models. Sometimes data modelers create too complex nested models. There are cases where nested levels can be merged into one, for a simpler model. Can we analyze the model to alert data modelers to these cases.
Better quality data
Here is a chance to go beyond what XP provides. You can add configurations that will do more complex validations on the data, and provide a part or Thymeleaf-fragment that outputs the results of that validation when viewing the page in mode="edit" .
This can be modeling dependencies between fields in some new way.
I don’t know if this makes sense, but it’s just some thoughts I’ve had.
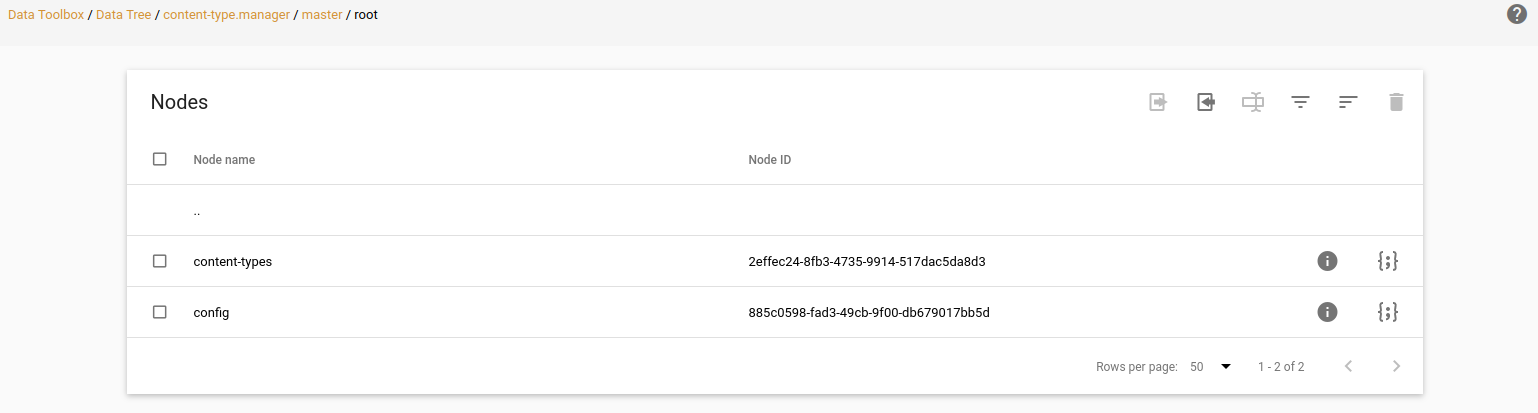
The generated XML is stored in the content-types folder (src/main/resources/site/content-types). Besides that, I use a custom repo that I named as “content-type.manager” to store some configurations of the tool and also some JSON data for each created content-type:
This current approach works great, but currently we can’t manage content types that weren’t initially created using the tool. Being able to edit previously “hand-maded” content types is something that I have in my mind and want to implement in near future.
To manage files in the file system I’m using a combination of some functions in this library created by @rbrastad and the I/O lib
I’ve implemented some updates related to the previous version that I’ve shown you guys, and there I have a “hide/show generated xml” button as you’ve requested
I hope to have another update that is worth sharing this next weekend!
Since I’ve rushed to implement some features to see if my idea was worth it, the code is a bit messy at the moment. I’ll refactor it a bit and also document some things before uploading it. After that I’ll share the code on Github ok?
Creating a repo for storing metadata related to building content types sounds like taking this in a wrong direction imho Since this is mainly being developer tool, beyond the content types itself - it should be stateless.
The app could then find and list all existing Content types, as well as create new ones simply by using the local file system
Another question, are you using the low-level Java API for creating and validating content types? AFAIK this should be capable of both parsing and exporting XML definitions.
After some thought, I couldn’t agree more with your suggestions… Thanks
I worked a bit more in the content type manager tool and things are starting to go into the right direction in my point of view:
I completely changed the way I was seeing / trying to solve the problem. Now the tool is basically a way to go from XML → JSON, mutate that JSON using a GUI, and then go back from JSON → XML.
I was facing some problems, mainly because most of the libraries that performs that conversions are not robust enough. The main problems were:
The transformation defined as the composition of the transformations XML → JSON → XML wasn’t preserved as the identity function;
The transformations weren’t preserving the order of the elements.
After some struggle I was able to find a XML ↔ JSON lib that worked perfectly.
As you can see I followed your suggestion to use the File System Access API
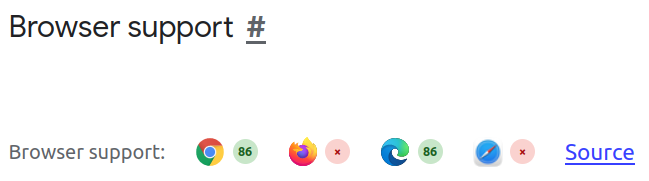
The only problem that I see is that it’s not currently supported by some browsers. What do you think?
There’s still a lot to work on, but I’d like to ask for some suggestions. @tom already gave me some good ones that I’ll be implementing in near future. Thank you Tom.
@tom, I hope to post the code on GitHub by the end of this week. I was expecting to release the code sooner, but since the @tsi suggestions, I started to mess around with a lot of different ways to attack the problem and therefore wasn’t focusing on the quality of it.
Your target audience is developers, and they will know how to get one of the supported browsers if they don’t already have it.
Personally I use progressive enhacement when I develop applications.
So I would create a base layer in my application that maybe output the result in the browser. And then I would enhance it to use the File System Access API for browsers that have support for it (by feature detecting it).
If you are not familiar with progressive enhacement, but want to get started using it. I recommend the Resilient web design podcast. It is only 7 episodes, and especially episode 5 and 6 contain really good information.
Adding support for Option Set (currently only field/item set are supported);
Fixing some edge cases that I was able to find, such as saving a cty with an empty form for example.
I’d also like to ask for something… is it possible for the Enonic Team to provide me a complex / huge content-type .xml file? I’d like to run some tests in a file like that.




 Since this is mainly being developer tool, beyond the content types itself - it should be stateless.
Since this is mainly being developer tool, beyond the content types itself - it should be stateless.





{kind=link}