Hi Gbi,
I have increased the vCPU & memory 7G.
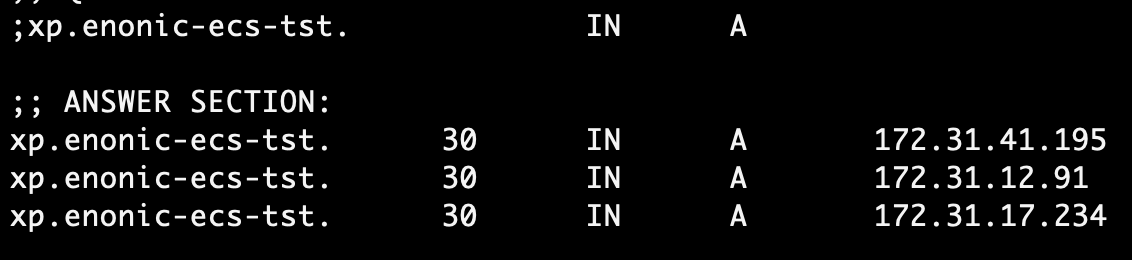
I am getting the same error from all the nodes.
master logs as follows:
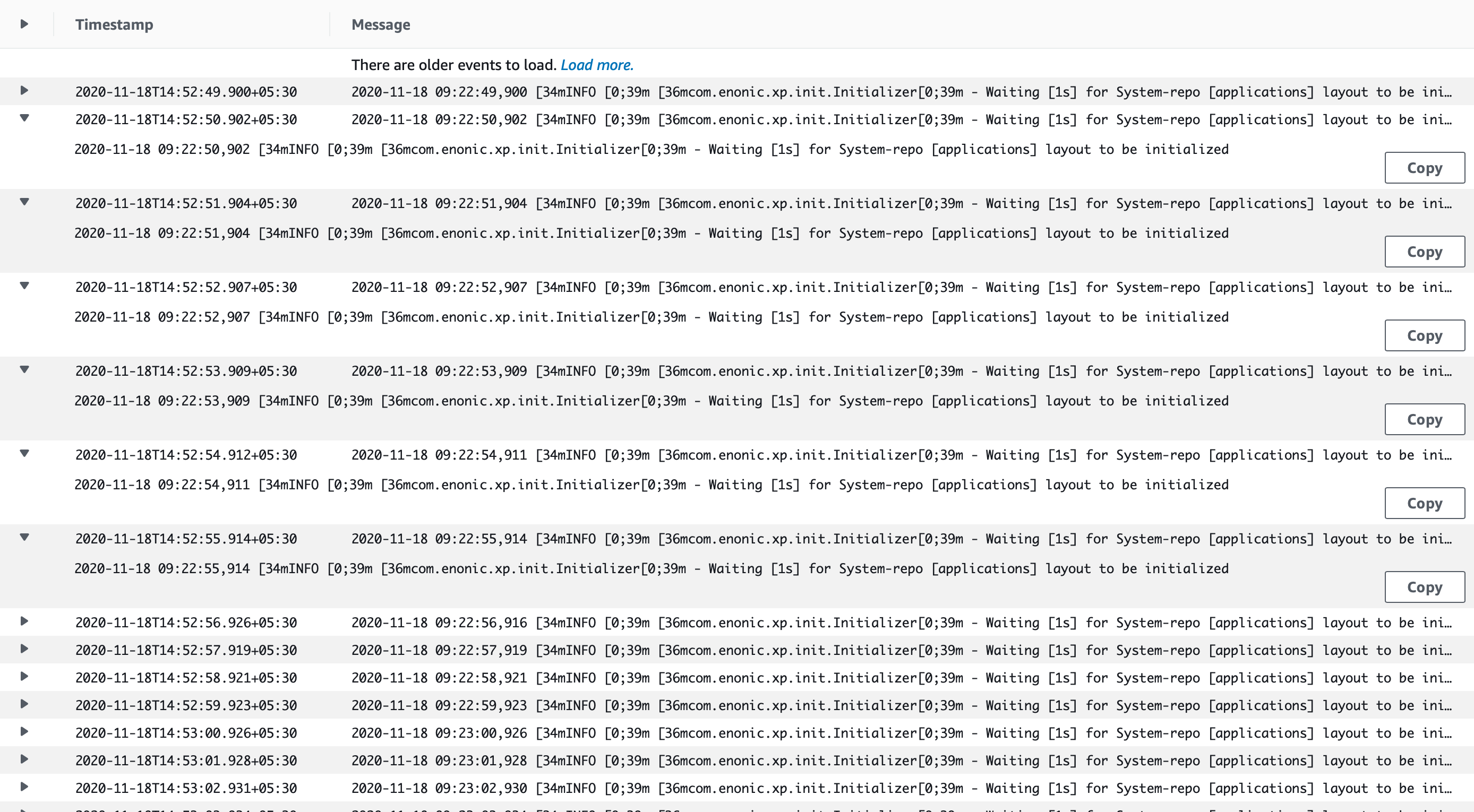
15:02:04.939 INFO c.e.x.l.i.framework.FrameworkService - Starting Enonic XP…
15:02:05.264 INFO c.e.x.l.i.p.ProvisionActivator - Installing 92 bundles…
15:02:06.260 INFO ROOT - bundle org.apache.felix.scr:2.1.16 (11)Starting with globalExtender setting: false
15:02:06.286 INFO ROOT - bundle org.apache.felix.scr:2.1.16 (11) Version = 2.1.16
15:02:07.465 WARN org.apache.tika.parsers.PDFParser - TIFFImageWriter not loaded. tiff files will not be processed
See https://pdfbox.apache.org/2.0/dependencies.html#jai-image-io
for optional dependencies.
J2KImageReader not loaded. JPEG2000 files will not be processed.
See https://pdfbox.apache.org/2.0/dependencies.html#jai-image-io
for optional dependencies.
15:02:07.504 WARN org.apache.tika.parser.SQLite3Parser - org.xerial’s sqlite-jdbc is not loaded.
Please provide the jar on your classpath to parse sqlite files.
See tika-parsers/pom.xml for the correct version.
15:02:08.030 INFO c.e.x.s.i.config.ConfigInstallerImpl - Loaded config for [com.enonic.xp.repo]
15:02:08.045 INFO c.e.x.s.i.config.ConfigInstallerImpl - Loaded config for [com.enonic.xp.server.trace]
15:02:08.071 INFO c.e.x.s.i.config.ConfigInstallerImpl - Loaded config for [com.enonic.xp.cluster]
15:02:08.095 INFO c.e.x.s.i.config.ConfigInstallerImpl - Loaded config for [com.enonic.xp.elasticsearch]
15:02:08.146 INFO c.e.x.s.i.config.ConfigInstallerImpl - Loaded config for [com.enonic.xp.web.dos]
15:02:08.166 INFO c.e.x.s.i.config.ConfigInstallerImpl - Loaded config for [com.enonic.xp.server.shell]
15:02:08.260 INFO c.e.x.s.shell.impl.ShellActivator - Remote shell access is disabled
15:02:08.668 INFO c.e.x.s.internal.trace.TraceService - Call tracing is disabled in config
15:02:08.916 INFO c.e.x.c.i.a.c.AuditLogConfigImpl - Audit log is enabled and mappings updated.
15:02:08.969 INFO c.e.x.i.blobstore.BlobStoreActivator - Waiting for blobstore-provider [file]
15:02:08.971 INFO c.e.x.i.blobstore.BlobStoreActivator - Found blobstore-provider [file]
15:02:08.994 INFO c.e.x.i.blobstore.BlobStoreActivator - Registered blobstore [file] successfully
15:02:09.836 INFO org.elasticsearch.node - [d1b00043-fc5e-4829-8044-78da600e1d68] version[2.4.6], pid[1], build[NA/NA]
15:02:09.836 INFO org.elasticsearch.node - [d1b00043-fc5e-4829-8044-78da600e1d68] initializing …
15:02:09.841 INFO org.elasticsearch.plugins - [d1b00043-fc5e-4829-8044-78da600e1d68] modules [], plugins [], sites []
15:02:09.859 INFO org.elasticsearch.env - [d1b00043-fc5e-4829-8044-78da600e1d68] using [1] data paths, mounts [[/ (overlay)]], net usable_space [24.8gb], net total_space [29.4gb], spins? [possibly], types [overlay]
15:02:09.859 INFO org.elasticsearch.env - [d1b00043-fc5e-4829-8044-78da600e1d68] heap size [1.7gb], compressed ordinary object pointers [true]
15:02:09.861 WARN org.elasticsearch.env - [d1b00043-fc5e-4829-8044-78da600e1d68] max file descriptors [4096] for elasticsearch process likely too low, consider increasing to at least [65536]
15:02:11.547 INFO org.elasticsearch.node - [d1b00043-fc5e-4829-8044-78da600e1d68] initialized
15:02:11.547 INFO org.elasticsearch.node - [d1b00043-fc5e-4829-8044-78da600e1d68] starting …
15:02:11.613 INFO org.elasticsearch.transport - [d1b00043-fc5e-4829-8044-78da600e1d68] publish_address {10.0.29.203:9300}, bound_addresses {10.0.29.203:9300}
15:02:11.620 INFO org.elasticsearch.discovery - [d1b00043-fc5e-4829-8044-78da600e1d68] enonic-ecs-tst/srniXcIPQBuUdl3PNoivMw
15:02:14.894 INFO org.elasticsearch.cluster.service - [d1b00043-fc5e-4829-8044-78da600e1d68] detected_master {267465a9-3baf-4da5-8b25-180fd2ba182c}{QfV307dSQOumgp94KAGuIA}{10.0.25.254}{10.0.25.254:9300}{data=false, local=false, master=true}, added {{aae88ded-b6d3-418a-90e2-7f7c64ab0bde}{m_aIkUGCTVGbkkVJrtAOmg}{10.0.17.210}{10.0.17.210:9300}{data=false, local=false, master=true},{267465a9-3baf-4da5-8b25-180fd2ba182c}{QfV307dSQOumgp94KAGuIA}{10.0.25.254}{10.0.25.254:9300}{data=false, local=false, master=true},{0e0e5621-486d-47cb-b9b8-28183928be88}{NPisFLcLSveaeBWc5aWCUg}{10.0.16.29}{10.0.16.29:9300}{data=false, local=false, master=false},}, reason: zen-disco-receive(from master [{267465a9-3baf-4da5-8b25-180fd2ba182c}{QfV307dSQOumgp94KAGuIA}{10.0.25.254}{10.0.25.254:9300}{data=false, local=false, master=true}])
15:02:14.949 INFO org.elasticsearch.node - [d1b00043-fc5e-4829-8044-78da600e1d68] started
15:02:15.067 INFO c.e.x.c.impl.ClusterManagerImpl - Adding cluster-provider: elasticsearch
15:02:15.388 INFO org.elasticsearch.cluster.service - [d1b00043-fc5e-4829-8044-78da600e1d68] added {{7c32f499-b281-4098-9e17-cc582b6b2be3}{2za6n9LtRaqsmONXsBBHeg}{10.0.0.99}{10.0.0.99:9300}{data=false, local=false, master=false},{c5a40605-aa77-4953-b17b-c97b00b296de}{XnOr-sEBQOOYvrog2QInMQ}{10.0.11.109}{10.0.11.109:9300}{data=false, local=false, master=false},{bd16dfd8-56df-4e0d-85e3-8d13cb34cd21}{4Qj44JbKSFqGeTonzWLNTg}{10.0.24.198}{10.0.24.198:9300}{data=false, local=false, master=false},}, reason: zen-disco-receive(from master [{267465a9-3baf-4da5-8b25-180fd2ba182c}{QfV307dSQOumgp94KAGuIA}{10.0.25.254}{10.0.25.254:9300}{data=false, local=false, master=true}])
15:02:15.408 INFO org.eclipse.jetty.util.log - Logging initialized @11156ms to org.eclipse.jetty.util.log.Slf4jLog
15:02:15.592 INFO org.eclipse.jetty.server.Server - jetty-9.4.28.v20200408; built: 2020-04-08T17:49:39.557Z; git: ab228fde9e55e9164c738d7fa121f8ac5acd51c9; jvm 11.0.8+10
15:02:15.624 INFO org.eclipse.jetty.server.session - DefaultSessionIdManager workerName=d1b00043-fc5e-4829-8044-78da600e1d68
15:02:15.626 INFO org.eclipse.jetty.server.session - No SessionScavenger set, using defaults
15:02:15.628 INFO org.eclipse.jetty.server.session - d1b00043-fc5e-4829-8044-78da600e1d68 Scavenging every 600000ms
15:02:15.642 INFO o.e.j.server.handler.ContextHandler - Started o.e.j.s.ServletContextHandler@f17462c{/,null,AVAILABLE,@xp}
15:02:15.643 INFO o.e.j.server.handler.ContextHandler - Started o.e.j.s.ServletContextHandler@2169a7fb{/,null,AVAILABLE,@api}
15:02:15.644 INFO o.e.j.server.handler.ContextHandler - Started o.e.j.s.ServletContextHandler@5b6082f8{/,null,AVAILABLE,@status}
15:02:15.658 INFO o.e.jetty.server.AbstractConnector - Started xp@668df19d{HTTP/1.1, (http/1.1)}{0.0.0.0:8080}
15:02:15.660 INFO o.e.jetty.server.AbstractConnector - Started api@106a9ccf{HTTP/1.1, (http/1.1)}{0.0.0.0:4848}
15:02:15.661 INFO o.e.jetty.server.AbstractConnector - Started status@5ffc627c{HTTP/1.1, (http/1.1)}{0.0.0.0:2609}
15:02:15.662 INFO org.eclipse.jetty.server.Server - Started @11410ms
15:02:15.671 INFO c.e.xp.web.jetty.impl.JettyActivator - Started Jetty
15:02:15.672 INFO c.e.xp.web.jetty.impl.JettyActivator - Listening on ports 8080, 4848 and 2609
15:02:16.781 INFO c.e.x.c.i.a.ApplicationRegistryImpl - Registering configured application com.enonic.xp.app.system bundle 87
15:02:16.820 INFO c.e.x.c.i.a.ApplicationRegistryImpl - Registering configured application com.enonic.xp.app.applications bundle 89
15:02:16.837 INFO c.e.x.c.i.a.ApplicationRegistryImpl - Registering configured application com.enonic.xp.app.main bundle 90
15:02:16.843 INFO c.e.x.c.i.a.ApplicationRegistryImpl - Registering configured application com.enonic.xp.app.standardidprovider bundle 91
15:02:16.845 INFO c.e.x.c.i.a.ApplicationRegistryImpl - Registering configured application com.enonic.xp.app.users bundle 92
15:02:16.846 INFO E.F.org.apache.felix.framework - FrameworkEvent STARTLEVEL CHANGED
15:02:16.847 INFO c.e.x.l.i.framework.FrameworkService - Started Enonic XP in 11909 ms
15:02:20.460 ERROR c.e.x.c.impl.ClusterManagerImpl - Provider elasticsearch not healthy: {
“cluster_name” : “enonic-ecs-tst”,
“status” : “red”,
“timed_out” : true,
“number_of_nodes” : 7,
“number_of_data_nodes” : 0,
“active_primary_shards” : 0,
“active_shards” : 0,
“relocating_shards” : 0,
“initializing_shards” : 0,
“unassigned_shards” : 4,
“delayed_unassigned_shards” : 0,
“number_of_pending_tasks” : 0,
“number_of_in_flight_fetch” : 0,
“task_max_waiting_in_queue_millis” : 0,
“active_shards_percent_as_number” : 0.0
}
15:02:26.466 ERROR c.e.x.c.impl.ClusterManagerImpl - Provider elasticsearch not healthy: {
“cluster_name” : “enonic-ecs-tst”,
“status” : “red”,
“timed_out” : true,
“number_of_nodes” : 7,
“number_of_data_nodes” : 0,
“active_primary_shards” : 0,
“active_shards” : 0,
“relocating_shards” : 0,
“initializing_shards” : 0,
“unassigned_shards” : 4,
“delayed_unassigned_shards” : 0,
“number_of_pending_tasks” : 0,
“number_of_in_flight_fetch” : 0,
“task_max_waiting_in_queue_millis” : 0,
“active_shards_percent_as_number” : 0.0
}
15:02:32.470 ERROR c.e.x.c.impl.ClusterManagerImpl - Provider elasticsearch not healthy: {
“cluster_name” : “enonic-ecs-tst”,
“status” : “red”,
“timed_out” : true,
“number_of_nodes” : 7,
“number_of_data_nodes” : 0,
“active_primary_shards” : 0,
“active_shards” : 0,
“relocating_shards” : 0,
“initializing_shards” : 0,
“unassigned_shards” : 4,
“delayed_unassigned_shards” : 0,
“number_of_pending_tasks” : 0,
“number_of_in_flight_fetch” : 0,
“task_max_waiting_in_queue_millis” : 0,
“active_shards_percent_as_number” : 0.0
}
15:02:38.473 ERROR c.e.x.c.impl.ClusterManagerImpl - Provider elasticsearch not healthy: {
“cluster_name” : “enonic-ecs-tst”,
“status” : “red”,
“timed_out” : true,
“number_of_nodes” : 7,
“number_of_data_nodes” : 0,
“active_primary_shards” : 0,
“active_shards” : 0,
“relocating_shards” : 0,
“initializing_shards” : 0,
“unassigned_shards” : 4,
“delayed_unassigned_shards” : 0,
“number_of_pending_tasks” : 0,
“number_of_in_flight_fetch” : 0,
“task_max_waiting_in_queue_millis” : 0,
“active_shards_percent_as_number” : 0.0
Thanks & Regards,
Suranga