Hello!
We have near 15000 objects in our Enonic instance and when we do a query
fulltext(‘data.*’, ‘h7’, ‘OR’)
It returns us near 1300 objects even if there are no hits for such text at all. Also, we have found that it works this way with numbers and if we replace ‘7’ to any letter it brings much less results.
Can it be some kind of a bug related to searching text with numbers?
And Is there any advice on how to make it return more accurate results?
Could you try not using “data.*” as search-field, this will include all kind of fields, e.g id-fields. Try using the “_allText” -field that will only consider the fields configured to be indexed as fulltext and see if the results are more as expected?
Ok, I need to look into his tomorrow too see if the resulting search sent to ES i too broad, I’m not at work today.
Btw ,what are you trying to achieve by this search? The fulltext-way of searching is expanding, meaning that it broadens the search to include all possible hits, and then using the ranking to order the results, e.g doing a fulltext-query for “h” on all fields will not accomplice much. I’m not sure at the moment without digging deeper into the function at es-level, but there may be some default fuzziness even for short terms like this. That the h7 yields more results that h6 is most likely random.
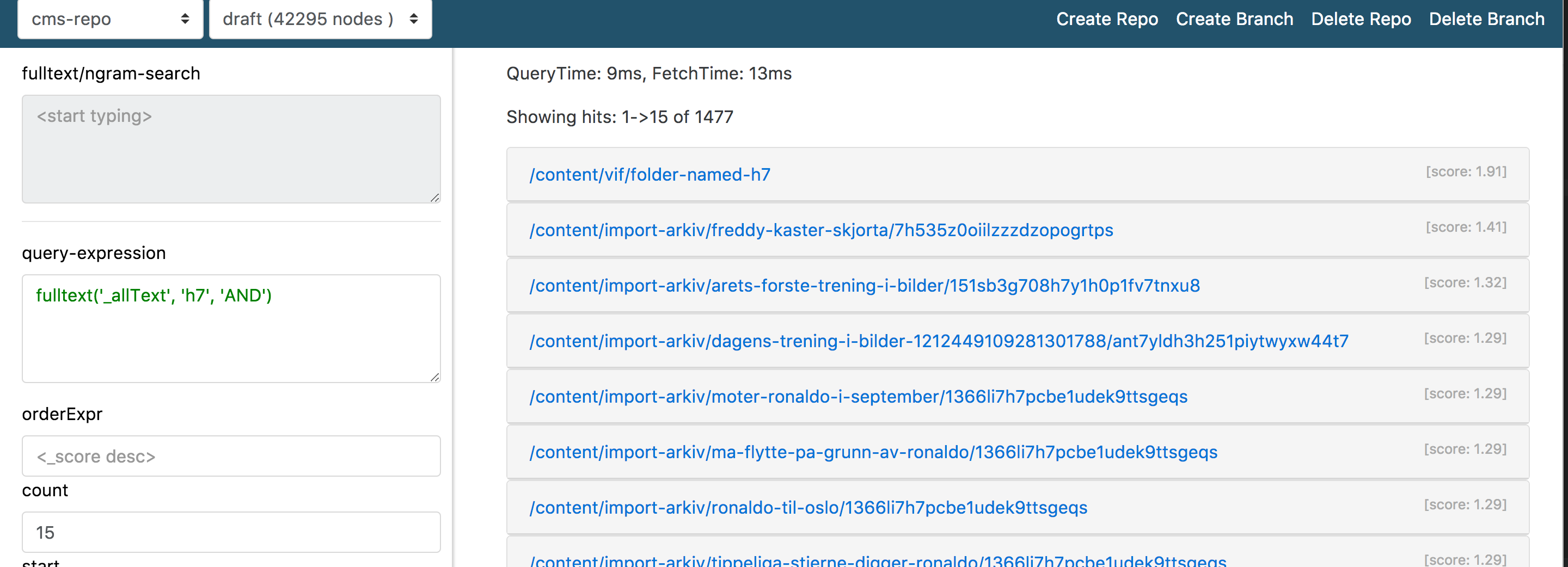
E.g, this is the result of some random repository I tested against. The document that actually contains the “h7” phrase as a standalone phrase is ranked at the top
The only reason why I’m asking this is that we have a search page and search results are separated there on different categories, like: employees, news, services, etc. And our client curious why does he gets search results in “employees” category on “h7” if there should not be hits at all. Also, it would be good if it’s possible to optimize somehow.
Ok, sir, here is an explanation about what is happening:
The word-tokenizer we use for the fulltext search are quite greedy (which is the default behaviour for the ES-filter we use in the deep) - splitting words on letter/numeric.
E.g,
“Wi-Fi” is indexed as “Wi” and “Fi”
“SD500” is indexed as “SD” and “500”
This is done both search and index-time.
So, when searching for h7, it will be tokenized into “h” and “7”. In addition you send the “OR”, meaning that all documents that will match “h” or “7” will be in the search result.
Its possible to e.g turn off the search-time split of h7, but this will impact other more relevant searches:
E.g You index a document containing a string “Sony KD-65XD8505”
This will be indexed as [“Sony”, “KD”, “65”, “XD”, “8505”]
If searching for “65XD9505”, you will get no hits with no search-time string/number tokenizer turned off, while a search for the same with string/number-tokenizer turned on will yield a high score for the document.
We will do some more testing here, and see what solution will fit most scenarios. Maybe we will open up for more configuration of search-time analyzing.
This is a very nice explanation. I would even suggest adding it to the documentation.
Now I can describe this in better words to our client and I have also got thoughts on how to optimize it.
Yes, in this case it will search for the ‘phrase’ h7, so it will narrow the search. You will still get hits on e.g “0v8h7zm” since it contains the token ‘h7’, but it will certainly narrow the results a lot. Be careful then, if user inputs more that one word, since then the full phrase has to match, so only apply when searching for one single word.
Also, I have one more question:
Does the search also split the phrase if there are comas(’,’), dots(’.’) or any other signs like this? And will it search for this signs? What will happen, for example, if I query ‘…’ or ‘!!!’?
In this case, fulltext finds nothing, but ngram returns the whole repo.
Thanks!
How do one do this? Can it be done per query? If so one could fire two queries. One with and one without.
Depending upon how many results one wants to show you could use the multiRepoConnection query and get scoring and merge the results.